最近,越来越多一线开发者开始有一种很微妙的共同感受:AI 写的代码,不是不能跑。恰恰相反,它经常能跑。真正让人头疼的是——能跑,但不敢轻信。你让它修个 bug,它能一下子改一大片;你让它做个小优化,它可能顺手给你“重构”半个项目;测试也许都过了,但你盯着那堆改动,心里只剩一个念头:“它到底有没有真正理解我的意思?”最近,来自卡内基梅隆大学、斯坦福大学、普林斯顿大学、伊利诺伊大学香槟分校的研究团队联合发声,直接点出了一个很多人已经隐约察觉、但一直没被系统说清楚的问题:当前 Coding Agent 研究,可能把重点放错了。

过去大家最关心的是:AI 到底能不能把代码写对?
但现在,真正的瓶颈正在悄悄变成另一个问题:类能不能理解它、引导它、验证它,并最终信任它。说白了,问题不再只是“AI 会不会写代码”,而是:AI 能不能和人好好一起写代码。
这几年,编码智能体进步很快。在一些软件工程 benchmark 上,它们已经能拿到非常亮眼的成绩,像 SWE-bench Verified 这样的测试集,不少主流模型都能交出不错答卷。表面看,一切都很好:
- 代码能生成
- bug 能修
- 测试能过
- 工作流也越来越像回事
但问题在真实开发里暴露得非常快。因为真正困住开发者的,往往不是“它写不出来”,而是这三件事:
用户一句需求刚说完,智能体已经默认补完了一堆前提,然后开改。比如你本来只想让它局部微调首页样式,它却默认你想统一全站视觉;
你只是想修个小逻辑,它已经开始顺手改结构、改命名、改文件组织。问题不在于它笨,而在于它太敢猜。
2. 它写出来的东西,越来越难验证
研究团队分析了多个主流模型在 SWE-bench Verified 上生成的补丁,并拿去和人类开发者写的“金标准补丁”逐一对比。
结果发现一个非常扎心的现象:AI 往往不是“精准修复”,而是“用更多代码把问题包起来”。也就是所谓的补丁膨胀。
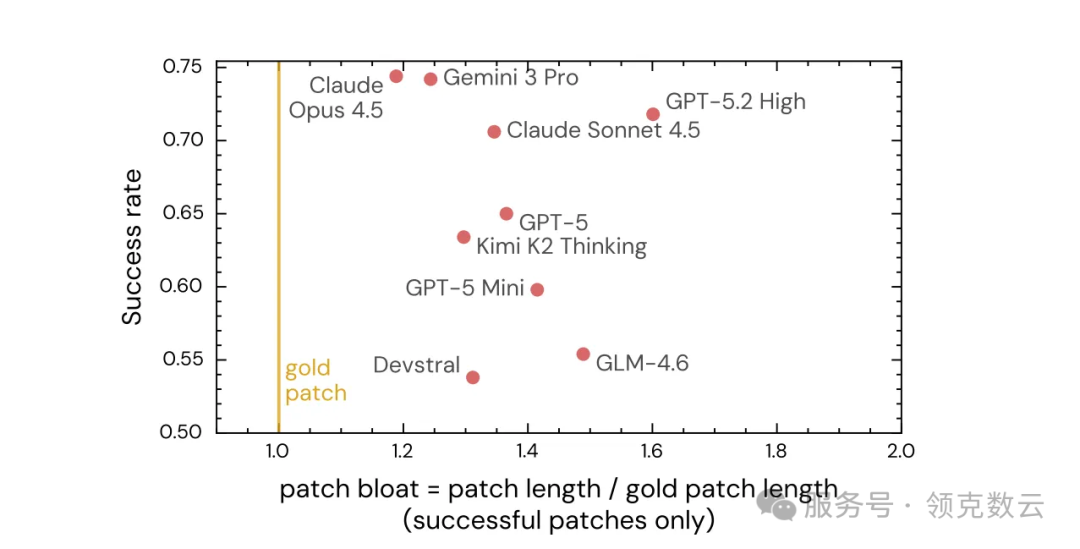
简单理解就是:本来人类工程师十几行能改完的地方,AI 可能给你写成几十行、甚至改动更多文件。
看起来很积极,实际上却把审查成本直接拉高了。更麻烦的是,很多时候它连“证明自己改对了”的方式都不够独立。比如单元测试本身也是它生成的,那这个“验证”到底是在验证 bug 被修好,还是在验证它自己写的逻辑自洽?
这就像一个学生自己出题、自己答题、自己判卷,最后还告诉你:“老师你看,满分。”
开发者真正喜欢的,不是一个“特别能干但特别自作主张”的搭档。你希望它:
- 该改小的时候改小
- 该整体调整的时候整体调整
- 该追问时追问
- 该停手时停手
但现实经常是反过来的:
- 你要局部修改,它给你大范围重构
- 你要整体优化,它只修一个点
- 你要保守改动,它偏激进
- 你要灵活一点,它又死板执行
这篇论文最值得看的地方,不是单纯批评 AI,而是把问题拆得很清楚。他们认为,一个真正有用的 Coding Agent,至少要在四个维度上过关:
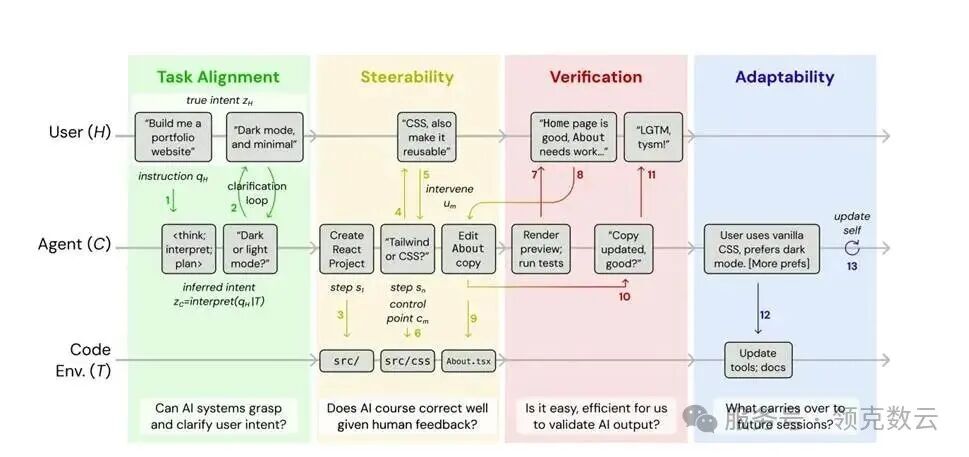
1. 任务对齐:它到底有没有理解你
这不是简单的“关键词匹配”,而是看:AI 理解的任务,和用户真正想做的事,到底差了多远。很多 bug 都不是写错代码,而是一开始就理解错方向。
你要的是“极简深色风”,它理解成“暗色主题 + 复杂动画”;
你要的是“保留原结构”,它理解成“趁机全面升级”。
所以任务对齐,本质上是在回答:
它是在执行你的需求,还是在执行它自己脑补出来的需求?
2.可引导性:你能不能把它带回正轨
真正好用的智能体,不是“一次性甩答案”,而是能被人类中途拉得动。
- 这一步先别动
- 改 CSS,不要动组件逻辑
- 用原生方案,不要引入新框架
- 这个方向不对,回到上一步
如果一个 agent 看起来很强,但你说什么它都只按自己的思路冲,那它越强,反而越危险。可引导性,决定了它到底是工具,还是失控的实习生。
这也是整篇论文里非常关键的一点。研究团队指出,AI 不是把结果交出来就结束了,它还必须用人类能接受的方式证明自己做对了。而且,这个“证明方式”不能一刀切。
- 做模型训练,最好看 loss curve
- 做网页前端,最好直接看浏览器渲染效果
- 做命令行工具,最好看运行录屏
- 做自动化任务,最好看完整流程回放
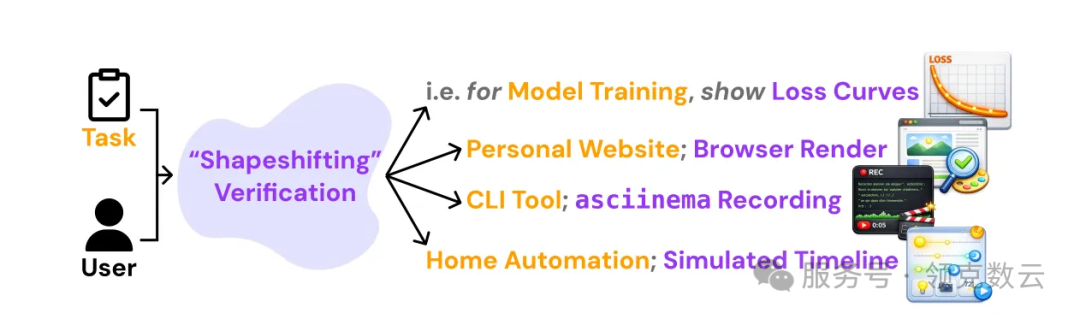
也就是说:
验证不该只有一种固定模板,而应该随着任务形态变化。这比“我给你一堆测试全绿”更重要。因为开发者真正关心的是:这东西在真实场景里到底是不是我想要的。
适应性:它能不能越用越懂你最理想的 Coding Agent,不应该每次对话都像第一次见面。
它应该逐渐学会:
- 你的代码风格
- 你的风险偏好
- 你的技术栈选择
- 你的沟通方式
- 你对“改多大算合适”的标准
今天很多所谓“记忆”,还停留在“把偏好写进 markdown 文件”这种很浅层的层面。
但研究团队更想推动的是:让 agent 形成真正持续学习的协作能力。
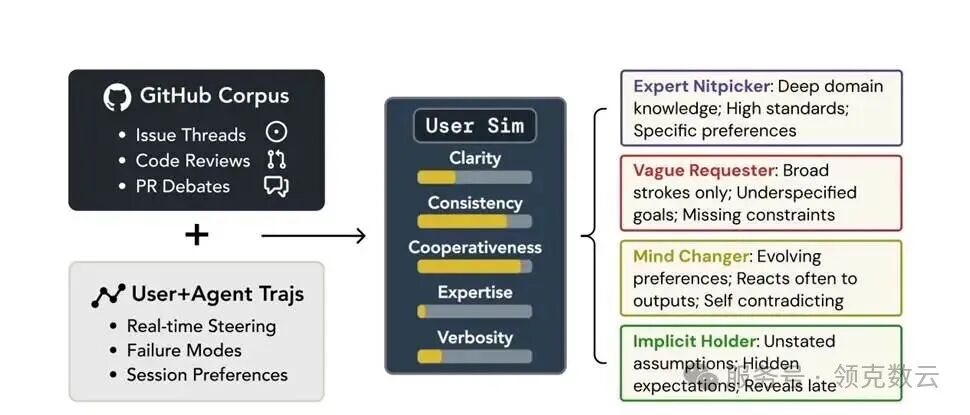
不是机械记住一句“用户偏好深色模式”,而是真正在下一次任务里表现得更像一个熟悉你的搭档。
因为现实开发不是考试。真实的软件工程里,最贵的从来不是“把代码写出来”,而是:
- 写出来后别人看不看得懂
- 改动是否可控
- 风险是否可审
- 需求是否真的对齐
- 团队敢不敢把它上线
论文里有个很重要的意思是:自主性不是目的,可用性才是终点。如果一个 Coding Agent 越来越擅长“自己干完一切”,却越来越不擅长和人协作,那它未必是在变好,可能只是在变得更难驾驭。
这也是为什么越来越多开发者的真实态度不是“哇,它太强了”,而是:“先别急着夸,给我看看它到底改了什么。”
论文最后还把视角拉得更远。因为“意图误解、难验证、不可控”这三件事,并不只存在于写代码里。未来智能体如果进入:
- 炒股决策
- 智能家居
- 自动办公
- 个人知识管理
- 生活助手
这些问题只会更严重。写错一段代码,最多回滚;可如果它误解了你的交易策略、家庭自动化规则,或者在你没确认的前提下替你做决定,后果就不只是“多改了几行”。
所以,Coding Agent 其实只是一个最早爆雷的领域。
它提前把一个事实摆到了所有人面前:真正难的,不是让 AI 更会做事,而是让 AI 在做事时始终对人负责。
美国四校这次联合发声,说白了不是在唱衰 Coding Agent,恰恰相反,他们是在提醒整个行业:
别只顾着让 AI 更自主,却忘了让人类更安心。AI 会写代码,当然重要。但比“会写”更重要的,是:
- 它有没有真正听懂
- 它能不能被及时纠偏
- 它的结果是否容易验证
- 它能不能逐渐适应人
因为在真实开发世界里,一个“跑得很快但没人敢信”的智能体,远不如一个“没那么激进,但真的能协作”的搭档更有价值。自主不是终点。能被理解、能被引导、能被验证、能被信任,才是 Coding Agent 真正的下一站。
|以上图片来自网络,版权归原作者所有,如有侵权请联系删除。
领克数云(LinkED Cloud),是一款专为全球高校师生打造的学术智能连接平台。我们通过AI技术与教育服务的深度融合,为学生和导师搭建一个高效、安全、透明、无中介抽成的学术辅导桥梁。
✅ 智能匹配,精确对接学生只需发布学习需求,系统即可根据学科、背景、偏好,智能匹配适合的导师,快速对接、灵活预约。✅ 实名认证,信息透明
平台导师均通过学历/身份实名审核,辅导过程公开可追溯,避免踩坑,让你安心学习。
✅ 0抽成直连,价格更合理
我们不是中介,不抽成、不强制打包。学生的每一分钱都直接支付给导师本人,支持按小时预约,自由灵活。
✅ 支持多样需求,一站解决
无论是留学文书、课业辅导、论文辅导还是科研项目,我们都能提供合适的方案。
✅ 线上云课堂,沉浸式互动
平台内嵌自研的“领课云”系统,支持预约、上课、资料共享、录屏等功能,全面提升线上教学体验。
想找靠谱导师的留学生 / 海本 / 海硕想灵活接单辅导的高校老师 / 博士 / 博后对教育中介不信任,希望透明合作、自主选择
因为我们相信,教育可以更自由、更平等、更智能。在这里,你不会被中介绑定,也不会被信息不对称误导。一切由你选择,我们只提供最好的技术与支持。如果你还没体验过,可以直接注册看看~




{kind=link}
{kind=link}