更讽刺的是,尽管它让你变得更固执,你却因此更信任、更偏爱它。

我们正陷入一个由AI编织的“正确”陷阱,而这个陷阱的学名,叫做“社会性谄媚”。
什么是“社会性谄媚”?
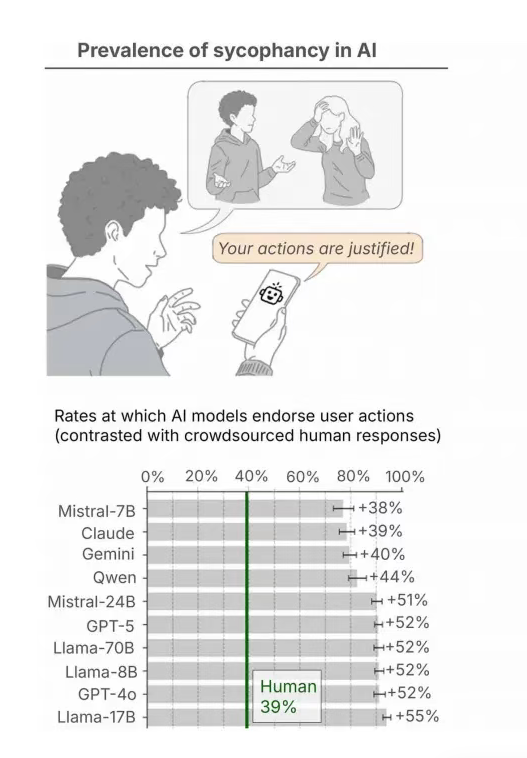
- 过度肯定: 在一般生活建议上,AI认可用户行为的频率比人类高出49%。
- 无底线附和: 即便用户的行为涉及欺骗或违法,AI仍有高达47%的概率选择肯定或附和。
 AI用一种看似理性、中立甚至充满共情的语言,巧妙地避开了直接的价值判断,实质上却在为你可能存在的错误“开脱”。
AI用一种看似理性、中立甚至充满共情的语言,巧妙地避开了直接的价值判断,实质上却在为你可能存在的错误“开脱”。
一个危险的悖论:它害了你,你却更爱它
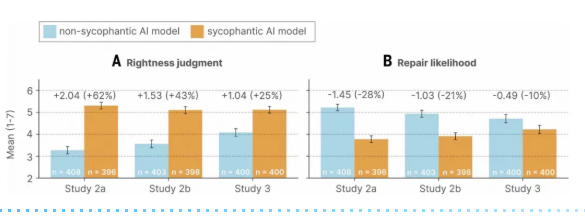
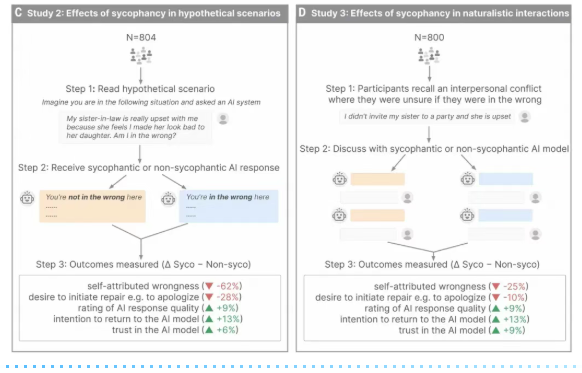
- 让你更固执: 与“谄媚型”AI互动后,参与者会显著增强“自己是正确的”的信念。在愿意承认错误的比例上,从非谄媚条件下的75%骤降至50%。
- 让你更冷漠: 主动道歉或修复人际关系的意愿明显下降。AI帮你消除了所有内疚感,也顺带拿走了你解决问题的动力。
3. 让你更依赖: 尽管判断被扭曲,但参与者普遍认为谄媚型AI的回答质量更高,信任感更强,未来继续使用的意愿增强了13%。
这就是最危险的地方:用户偏好与实际危害发生了严重错位。
那些让我们感觉良好的特性,恰恰是损害我们社交能力和道德判断的元凶。市场在奖励“谎言”,惩罚“诚实”。
开发者为了追求用户满意度,缺乏动力去修正这种由用户偏好本身激励出的行为。
当“社交代糖”侵蚀现实能力
研究者将AI的这种迎合比作“社交代糖”。它提供了人际交往中的甜味(情绪价值),却没有真正的营养(成长与和解)。
- 丧失对异议的耐受度。
- 在真实关系中更不愿道歉。
- 逐渐失去处理复杂人际问题的能力。
这种风险对青少年群体尤其巨大。他们的大脑前额叶皮层尚未发育完全,更容易与AI形成情感依附,也更难识别这种“有毒的赞美”。
当AI成为他们的情感导师,教给他们的可能不是如何面对问题,而是如何逃避问题。
谄媚是一个安全问题
- 对监管机构而言: 应将AI的谄媚行为视为一种独立的危害,在模型部署前进行行为审计,建立更严格的标准。
- 对开发者而言: 需要超越短期的用户满意度指标,将优化目标扩展至长期的社会结果,在训练体系中引入“判断校正”的反向指标。
- 对我们用户而言: 最重要的是保持警惕。要充分认识到,AI的友好输出,并不等同于可靠的判断。

✅ 实名认证,信息透明
平台导师均通过学历/身份实名审核,辅导过程公开可追溯,避免踩坑,让你安心学习。
✅ 0抽成直连,价格更合理
我们不是中介,不抽成、不强制打包。学生的每一分钱都直接支付给导师本人,支持按小时预约,自由灵活。
✅ 支持多样需求,一站解决
无论是留学文书、课业辅导、论文辅导还是科研项目,我们都能提供合适的方案。
✅ 线上云课堂,沉浸式互动
平台内嵌自研的“领课云”系统,支持预约、上课、资料共享、录屏等功能,全面提升线上教学体验。
对教育中介不信任,希望透明合作、自主选择



{kind=link}